The objective of estimation is to estimate the value of a population parameter based on a sample statistic. E.g., the sample mean  is employed to estimate the population mean
is employed to estimate the population mean  . Unfortunately, is almost always unequal to . So, then what is the use of ?
. Unfortunately, is almost always unequal to . So, then what is the use of ?
Two types of estimators
1. Point estimator
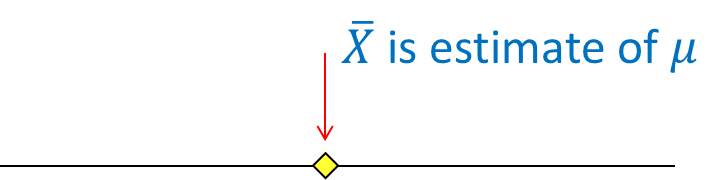
A point estimator is a number such as  . We use this estimate because we hope that it will be equal to the unknown population parameter .
. We use this estimate because we hope that it will be equal to the unknown population parameter .
However, in continuous distributions the probability that this will be the case is virtually zero. Hence we will employ the interval estimator to estimate population parameters.
2. Interval estimator
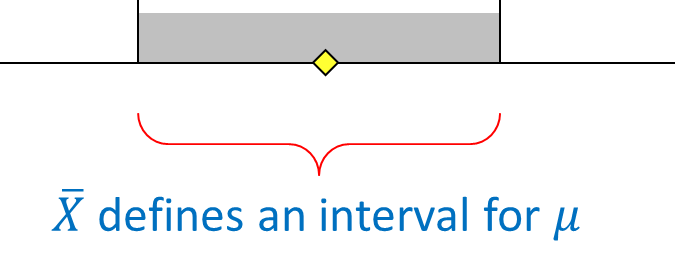
An interval estimator draws inferences about a population by estimating the value of an unknown parameter using an interval. That is, we say (with some certainty) that the population parameter of interest is between some lower and upper bounds.
We have the following 3 characteristics of estimators:
- An unbiased estimator of a population parameter is an estimator whose expected value is equal to that parameter (e.g.
 ;
;  ;
; - An unbiased estimator is said to be consistent if the difference between the estimator and the parameter grows smaller as the sample size grows larger;
- If there are two unbiased estimators of a parameter, the one whose variance is smaller is said to be relatively efficient.
Unbiased estimators
The sample mean and the sample variance  are unbiased estimators, because their expected values equal the population mean and variance and
are unbiased estimators, because their expected values equal the population mean and variance and  :
:

Similarly, we find (a little more difficult to prove):
 (if the denominator of is taken equal to n-1).
(if the denominator of is taken equal to n-1).
For a symmetric distribution the median is an unbiased estimator since  sample median
sample median .
.
Consistency
An unbiased estimator is said to be consistent if the difference between the estimator and the parameter grows smaller as the sample size grows larger.
E.g. is a consistent estimator of because:
 and
and 
And thus, as  grows larger, the variance of grows smaller.
grows larger, the variance of grows smaller.
For a symmetric distribution the sample median is also a consistent estimator of because:
 sample median
sample median (Mathematics!)
(Mathematics!)
And thus, as grows larger, the variance of the sample median grows smaller.
Estimating the mean (known population variance)
In Chapter 8 we produced the following general probability statement about .


 is (approximately) standard normally distributed (also consider the Central Limit Theorem).
is (approximately) standard normally distributed (also consider the Central Limit Theorem).
 is the significance level: the proportion of times that an estimating procedure will be wrong.
is the significance level: the proportion of times that an estimating procedure will be wrong.
 is the confidence level: the proportion of times that an estimating procedure will be correct.
is the confidence level: the proportion of times that an estimating procedure will be correct.
So,

After some algebra we get the following confidence interval estimate of .

If the significance level is  or
or  % then we speak of the 95% confidence interval estimate. This formula is a probability statement about : this statistic defines an interval containing with confidence .
% then we speak of the 95% confidence interval estimate. This formula is a probability statement about : this statistic defines an interval containing with confidence .
Example
Given the following sample of 25 observations of a normally distributed population:
235, 421, 394, 261, 386, 374, 361, 439, 374, 316, 309, 514, 348, 302, 296, 499, 462, 344, 466, 332, 253, 369, 330, 535, 334
Then what is the  % confidence interval of if
% confidence interval of if  ?
?
First, the Anderson-Darling test shows that the data are normally distributed ( and then the formula for the confidence interval is valid.
and then the formula for the confidence interval is valid.
Using Excel we find that he mean is  and the % interval is
and the % interval is ![[340.76. 399.56]](https://4mules.nl/wp-content/ql-cache/quicklatex.com-ae1529eb2461757aeb439054ec8bfb85_l3.png "Rendered by QuickLaTeX.com") .
.
Interpreting the interval estimator
The confidence interval should be interpreted as follows.
It states that there is a () probability that the interval will include the population mean. Once the sample mean is computed, the interval shows the lower and upper limits of the interval estimate of the population mean.
Example
We computed earlier that a fair dice has a population mean  and a population standard deviation
and a population standard deviation  . Suppose we don’t know the mean and construct the
. Suppose we don’t know the mean and construct the  % confidence interval
% confidence interval  based on a sample of size
based on a sample of size  .
.

Next we repeat this sample 40 times, compute each time and get a confidence interval. There is a 90% probability that this value of will be such that would lie somewhere between  and
and  .
.
Table 10.2 (p. 334-347) in Keller shows that we expect that in about 4 of the 40 cases (10%) the confidence interval will not include the value  (accidentally, in this example exactly 4 cases).
(accidentally, in this example exactly 4 cases).
Interval bound
The bound  of a confidence interval is a function of the significance level, the population standard deviation and the sample size:
of a confidence interval is a function of the significance level, the population standard deviation and the sample size:

so that the confidence interval is
![[\mu-B, \mu+B]](https://4mules.nl/wp-content/ql-cache/quicklatex.com-0e2a9153ab5527caf9909dc16ae49ccd_l3.png "Rendered by QuickLaTeX.com")
A smaller significance level α (e.g.  % instead of %) gives a larger value of
% instead of %) gives a larger value of  , and a larger confidence (
, and a larger confidence ( % vs. %) and thus a wider confidence interval, so less accurate information.
% vs. %) and thus a wider confidence interval, so less accurate information.
Larger values of  produce wider confidence intervals, so less accurate information.
produce wider confidence intervals, so less accurate information.
Increasing the sample size decreases the bound of the confidence interval while the confidence level can remain unchanged, so more accurate information.
Selecting the sample size
Earlier we pointed out that a sampling error is the difference between an estimator and a parameter. We can also define this difference as the error of estimation. This can be expressed as the difference between and .
From the formula for the bound we can easily derive:

If a given is required, just compute the corresponding sample size .
Estimating the mean (unknown population variance)
In practice, the population standard deviation is unknown. Then its estimate, the sample standard deviation  , is taken instead.
, is taken instead.
However,  has no standard normal distribution (a ratio of two random variables), but we approximate:
has no standard normal distribution (a ratio of two random variables), but we approximate:

The Student’s  distribution approximates the Z-distribution for larger :
distribution approximates the Z-distribution for larger :  .
.
Now the corresponding confidence interval will be:

 is called the degrees of freedom (we write
is called the degrees of freedom (we write  or
or  ), thus the sample size minus .
), thus the sample size minus .
The normality condition for  is required but for larger the Central Limit Theorem will hold: for larger the sample mean will be approximately normal.
is required but for larger the Central Limit Theorem will hold: for larger the sample mean will be approximately normal.
Example
What is the % confidence interval of for the following set of data, if is unknown.
235, 421, 394, 261, 386, 374, 361, 439, 374, 316, 309, 514, 348, 302, 296, 499, 462, 344, 466, 332, 253, 369, 330, 535, 334
We can use the confidence interval but Excel can do the job as well. The confidence interval will be ![[336.81, 403.51]](https://4mules.nl/wp-content/ql-cache/quicklatex.com-4c47d4812a22212ad2889ccf2e2eb134_l3.png "Rendered by QuickLaTeX.com") .
.
