(Keller 4-1, 2, 3, 4)
Population vs. Sample
A population consists of all objects of interest (e.g. all students at Erasmus University Rotterdam, approximately 35000 students). Usually the number of objects in a population is denoted as  , the population size).
, the population size).
A sample consists of a (random) selection from the population. For instance 100 students taken from all students at Erasmus University Rotterdam. Usually the number of objects in a sample is denoted as ( ≪), the sample size.
≪), the sample size.
Data types
The following data types are defined:
- Nominal / Categorical (text, no order, e.g. capital city: "Amsterdam", "Paris", "Bordeaux");
- Ordinal (nominal with some order, e.g. army ranks: "General", "Corporal", "Private");
- Interval (real numbers, e.g. profit:
 %);
%); - Ratio (interval with true zero point, e.g. weight: 80 kg).
Often the ratio type is not used, as is the case in the Keller book.
Numerical descriptive statistics
The most important descriptive statistics are the following:
- Measures of central location, e.g. mean, median, mode;
- Measures of variability, e.g. variance, standard deviation, range, coefficient of variation;
- Measures of relative standing, e.g. percentiles, Quartiles (
 , Interquartile Range
, Interquartile Range  ;
; - Graphical representation of data, e.g. boxplots, histograms;
- Measures of linear relationship, e.g. covariance, correlation, determination, regression equation.
Measures of central location
The following measures of central location are used.
- The arithmetic mean, also known as average, shortened to mean, is the most popular and useful measure of central location.
- It is computed by simply adding up all the (numerical) obervations and dividing the sum by the total number of observations
 ;
; - The population mean is
 ,
,  ;
; - The sample mean is
 ,
,  .
.
The arithmetic mean
- The arithmetic mean is appropriate for describing interval data, e.g. heights of people, marks of students, prices, etc.;
- A disadventage is that it is seriously affected by extreme values called outliers. E.g. if one observation is much larger than usual (by a typo), such as 579990 in the following observations:
 .
.
The median
The median is calculated by placing all observations in increasing order; the observation that falls in the middle is the median.
Example
Data:  (uneven, so there is a middle number);
(uneven, so there is a middle number);
Sort them from bottom to top, and find the middle; - The median is:
- The median is:  .
.
Example
Data:  (even);
(even);
Sort them from botton to top, and find the middle by averaging both middle numbers; The median is
The median is  .
.
The mode
The mode of a set of observations is the value that occurs most frequently. For example, of a number of international students, which nationality occurs most often?
If 10 students have the following nationalities: France, France, USA, China, Netherlands, France, China, France, Spain. Italy, then the mode is France.
A set of data may also have two, or more modes.
The mode can be used for all data types, though it is mainly used for nominal data.
Which is the best, mean or median?
The mean is used most frequently.
Example
The mean  and the median
and the median  .
.
Now suppose that the respondent who reported  actually reported
actually reported  (a typo). The mean changes sharply but the median does not change.
(a typo). The mean changes sharply but the median does not change.

The mean  (instead of
(instead of  ) and the median remains .
) and the median remains .
So, the median is less sensitive for outliers.
Measures of variability
There are several possible measures of variability, but why don't we just take the mean of the deviations from the mean as a measure of the spread? Unfortunately, this will always be zero:  ).
).
Then, why not take the absolute value of the deviations from the mean:  ? This would be possible but absolute value functions are difficult to handle mathematically.
? This would be possible but absolute value functions are difficult to handle mathematically.
Other possible measures are:
Range = max - min of the data;
Interquartile range IQR =  . For the explanations of quartiles see later.
. For the explanations of quartiles see later.
The variance is the mean squared deviations from the mean. Although this measure is not exactly what we want, it is used frequently and successfully in Statistics.
Variance and standard deviation
The variance and its related measure standard deviation, are most important measures in Statistics. They play a vital role in almost all statistical inference procedures.
The population variance is denoted by  and the population standard deviation is
and the population standard deviation is  .
.
The sample variance is denoted by  and the sample standard deviation is
and the sample standard deviation is  .
.
The population variance is:  , is the population size.
, is the population size.
The sample variance is:  , is the sample size.
, is the sample size. is called the degrees of freedom (df).
is called the degrees of freedom (df).
Interpreting the standard deviation
The standard deviation is used to compare the variability of a distribution and make a statement about the general shape of a distribution. If the histogram is bell-shaped, we can use the Empirical rule:
- Approximately 68% of all observations fall within one standard deviation of the mean;
- Approximately 95% of all observations fall within two standard deviations of the mean;
- Approximately 99.7% of all observations fall within three standard deviations of the mean.
If the distribution is normal, then these percentages are exact.
Range
The range of a set of interval data is the difference between the largest and smallest observation.
Example
Data set: 
The difference is 
Measures of relative standing
Measures of relative standing are designed to provide information about the position of particular values relative to the entire data set.
Percentile: the  percentile is the value for which
percentile is the value for which  % are less than that value and
% are less than that value and  % are greater than that value.
% are greater than that value.
Example
Suppose you scored in the  percentile on an exam. This means that 60% of the other scores were below yours, while 40% of the scores were above yours.
percentile on an exam. This means that 60% of the other scores were below yours, while 40% of the scores were above yours.
Quartiles
There are special names for the  ,
,  ,
,  percentile, named quartiles.
percentile, named quartiles.
- The first or lower quartile is labeled
 percentile;
percentile; - The second quartile is
 percentile (the median);
percentile (the median); - The third or upper quartile is labeled
 percentile.
percentile.
Interquartile range (IQR)
The quartiles can be used to create one more measure of variability, the interquartile range (IQR), which is defined as follows:
Interquartile range IQR
The interquartile range measures the spread of the middle  % of the observations. Large values of this statistic means that the
% of the observations. Large values of this statistic means that the  and
and  quartiles are far apart indicating a high level of variability.
quartiles are far apart indicating a high level of variability.
Example
IQR , according to Excel.
, according to Excel.
Boxplots and histograms
The boxplot is a technique that graphs a number of statistics, such as  (median),
(median),  , ICR and outliers.
, ICR and outliers.
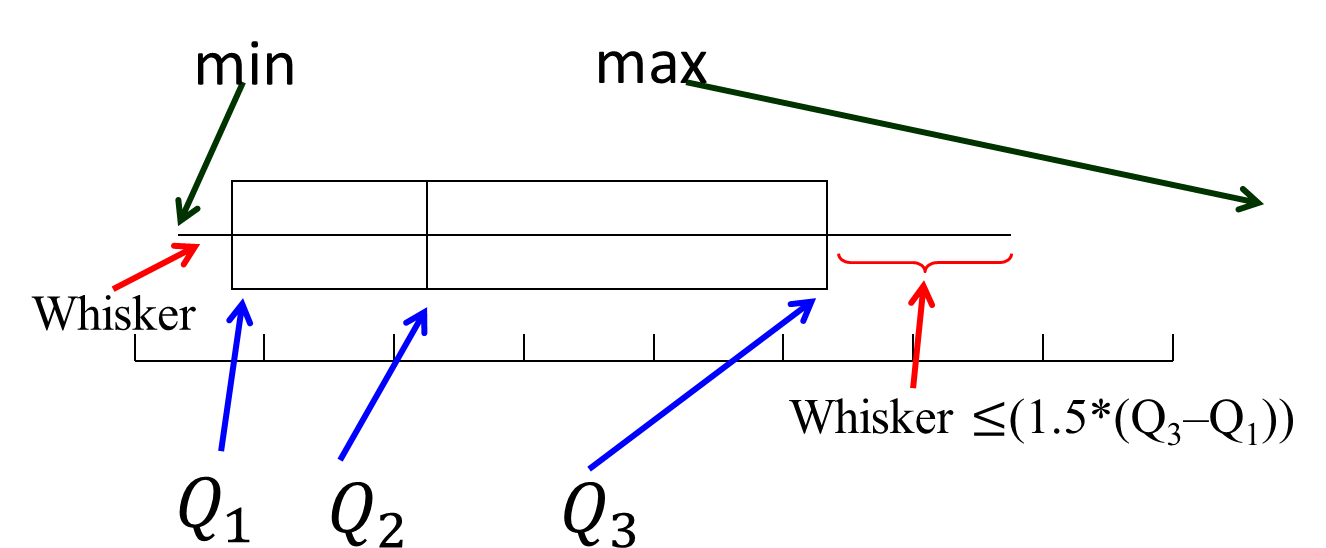
The horizontal lines extending to the left and right are called whiskers. Any points that lie outside the whiskers are called outliers. The whiskers extend outward to the smaller of 1.5 times the interquartile range or to the most extreme point that is not an outlier.
The following boxplots compare a number of US hamburger chains.
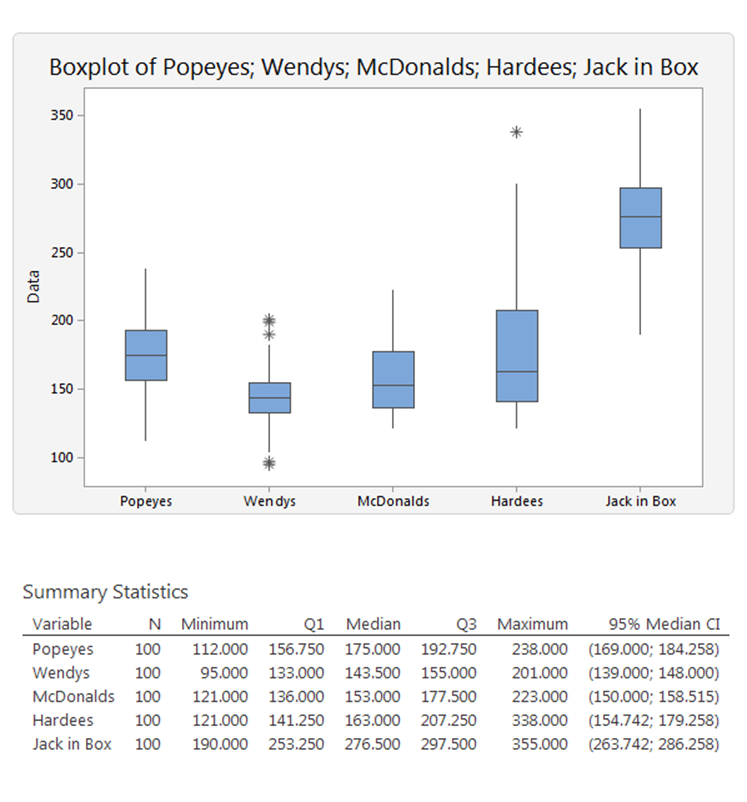
These hamburger chains are compared with respect to their service times. Wendy’s service time is shortest and least variable. Hardee’s has the greatest variability, while Jack-in-the-Box has the longest service times.
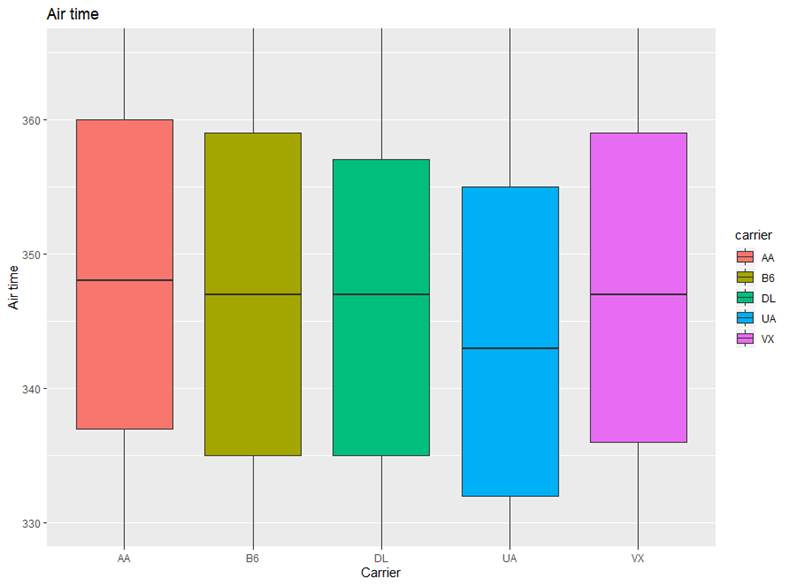
The following graph shows the boxplots of air time of 5 carriers flying from JFK to SFO. UA has the smallest median. the variability is almost the same.
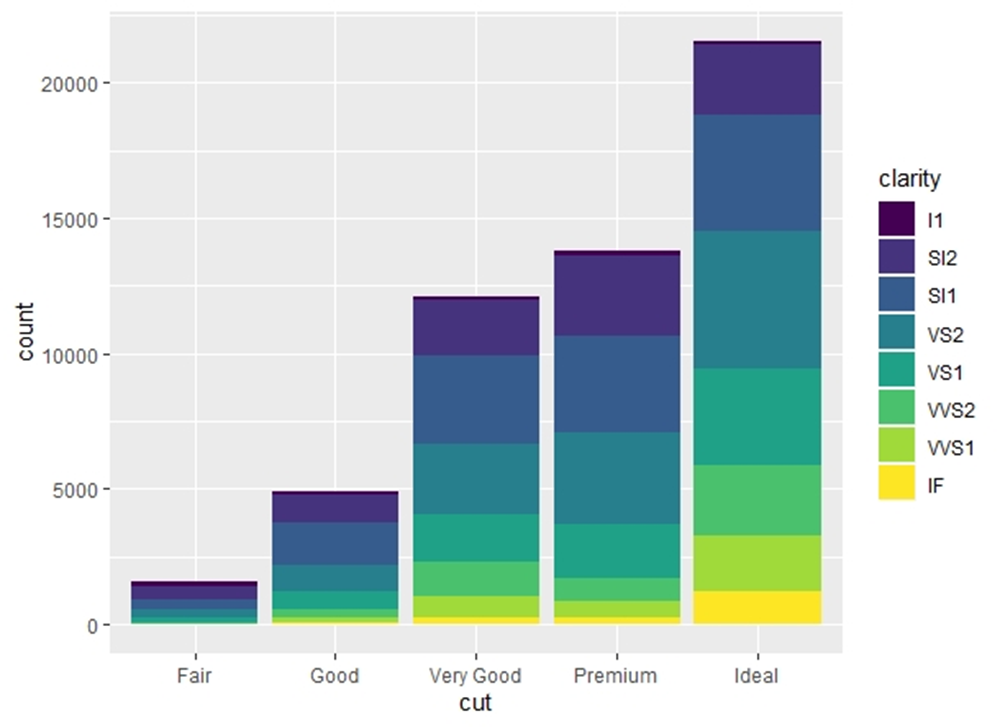
The following graphs (made by the programming language R and using the large data set Diamonds) show the distribution of the clarity of the various types of quality of diamonds. This data set contains about 22000 'ideal' cut diamonds, most of them have a clarity VS2 and only a few hundred clarity IF.
Measures of linear relationship
There are three numerical measures of linear relationship that provide information as to the strength and direction (positive / negative) of a linear relationship between two variables (if one exists).
- Covariance;
- Coefficient of correlation;
- Coefficient of determination.
Covariance
The population covariance between two variables  and
and  is defined as follows ( is the population size):
is defined as follows ( is the population size):

The sample covariance between the variables and is defined as follows ( is the sample size):

Example
The table below shows two samples and .
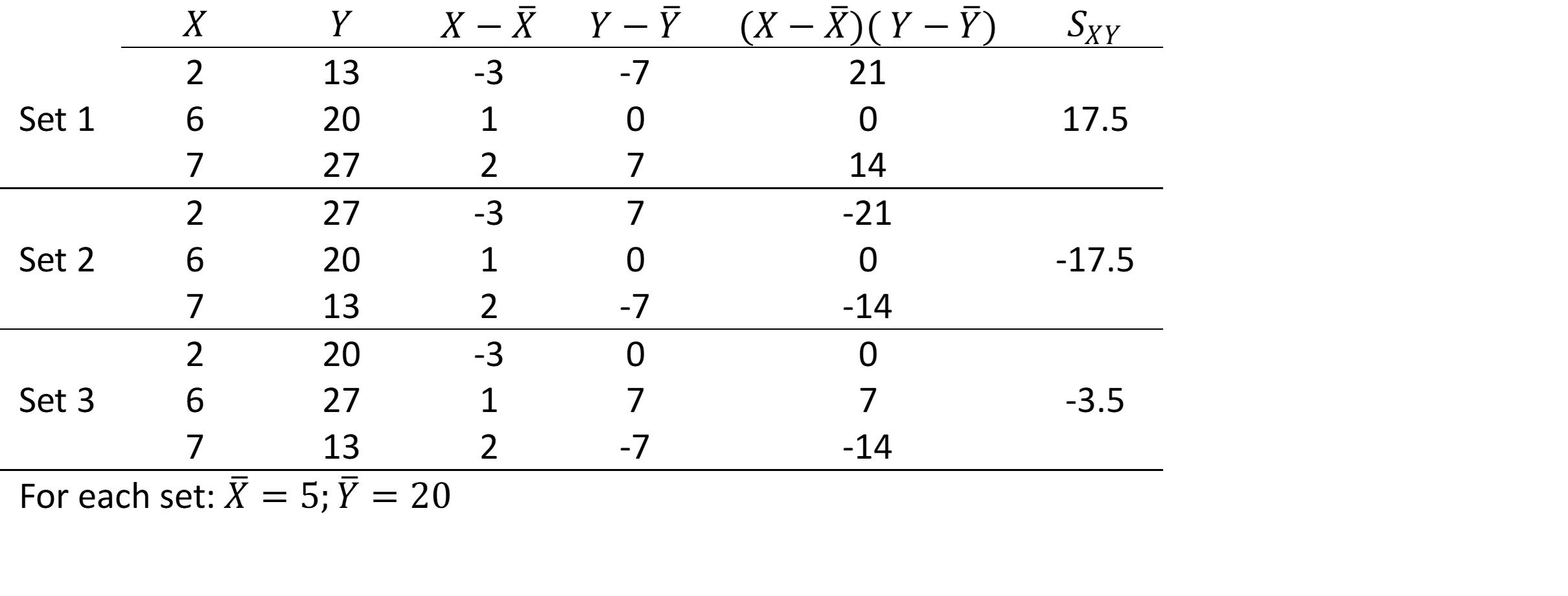
In each set the values of are the same and the values of are the same; the only thing that has changed is the order of the ’s.
- In Set 1: as increases, so does :
 is large and positive;
is large and positive; - In Set 2: as increases, decreases: is large and negative;
- In Set 3: as increases, does not in any particular way:
 is small (close to 0).
is small (close to 0).
In general we note:
- When two variables move in the same direction (both increase or decrease), the covariance is a ‘large’ positive number;
- When two variables move in opposite direction, the covariance is a ‘large’ negative number;
- When there is no particular pattern, the covariance is a ‘small’ number (close to 0).
However, what is large or and what is small?
Coefficient of correlation
The covariance has a disadvantage, it has not limited. A larger covariance in one situation does not mean a stronger relationship than a smaller covariance in another relationship. The coefficient of correlation solves this problem: it lies in the interval ![[-1,+1]](https://4mules.nl/wp-content/ql-cache/quicklatex.com-3a7f59e4731ba13889fddac0445ed87a_l3.png "Rendered by QuickLaTeX.com") . It is defined as the covariance divided by the standard deviations of the variables.
. It is defined as the covariance divided by the standard deviations of the variables.
The population coefficient of correlation is:

The sample coefficient of correlation is:

The coefficient of correlation answers the question: how strong is the association between and ?
The advantage of the coefficient of correlation over the covariance is that it has a fixed range from  to
to  (proven by Mathematics). If the two variables are very strongly and positively related, the coefficient value is close to (strong positive linear relationship). If the two variables are very strongly and negatively related, the coefficient value is close to (strong negative linear relationship). No straight linear relationship is indicated by a coefficient close to 0.
(proven by Mathematics). If the two variables are very strongly and positively related, the coefficient value is close to (strong positive linear relationship). If the two variables are very strongly and negatively related, the coefficient value is close to (strong negative linear relationship). No straight linear relationship is indicated by a coefficient close to 0.
The following graphs depict the relations of and for various coefficients of correlation, varying from to .
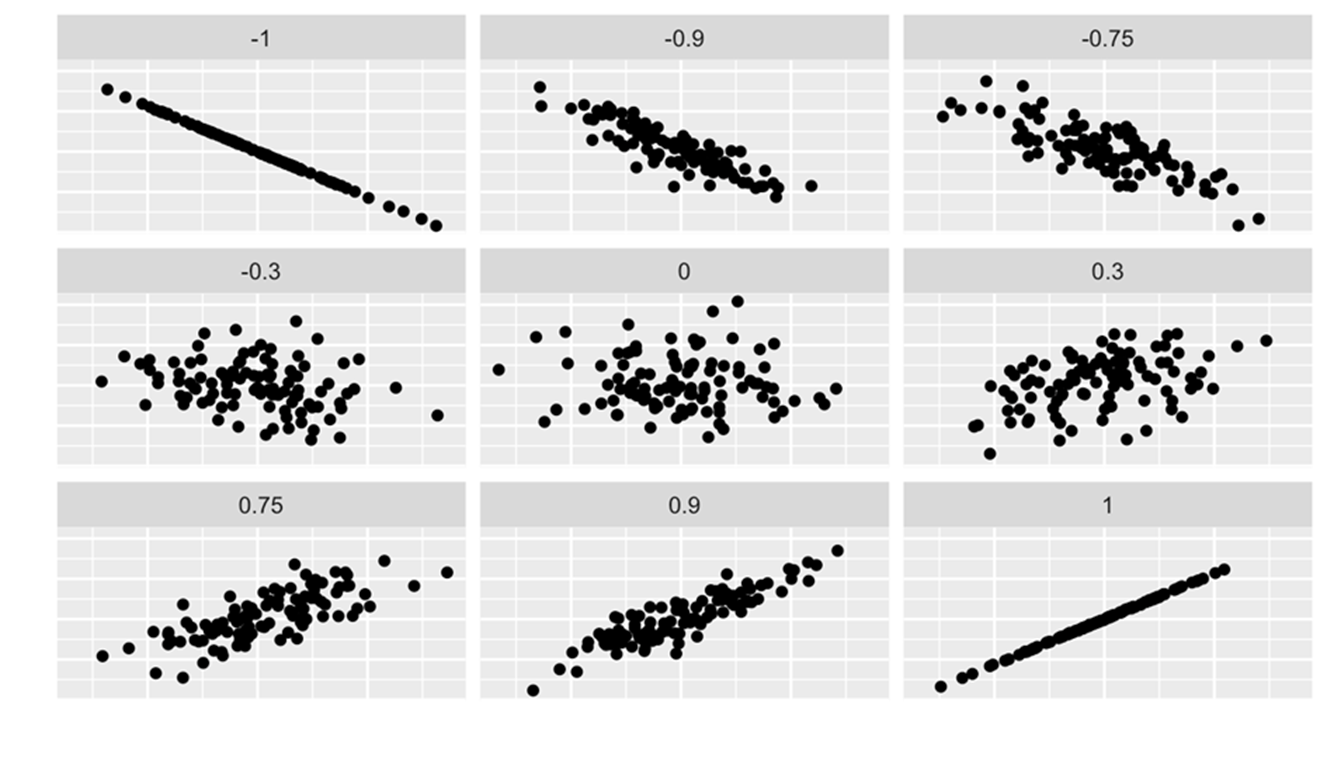
We can judge the coefficient of correlation in relation to its proximity to -1, 0, +1.
We have another measure that can precisely be interpreted: the coefficient of determination. It is calculated by squaring the coefficient of correlation and we denote it  . The coefficient of determination measures the amount of variation in the dependent variable that is explained by the variation in the independent variable.
. The coefficient of determination measures the amount of variation in the dependent variable that is explained by the variation in the independent variable.
The scatter plot
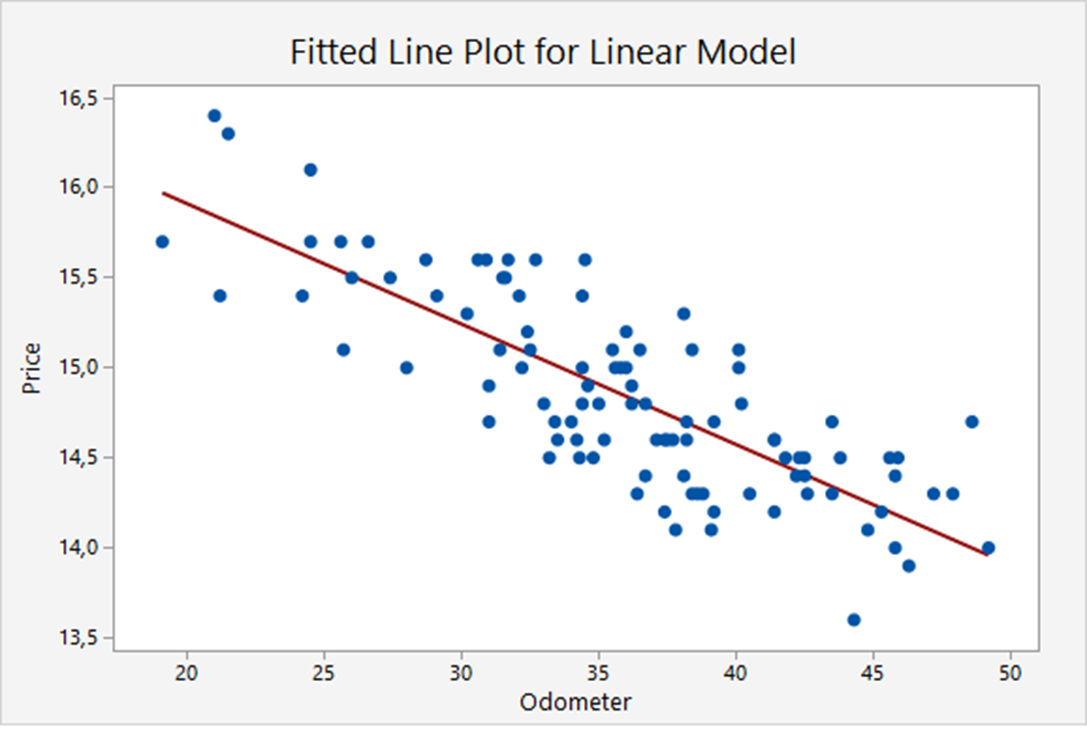
This scatter plot depicts the trade-in values for 100 basic models of a certain type of car, only based on the odometer readings, see Keller Example 16.2. There are 2 variables: Price and Odometer, so it is a univariate model. The blue dots represent the data (Price, Odometer) of each particular car. The red line is the so-called regression line. The regression line in this example is:
Price  Odometer
Odometer
Least squares method
A scatter plot indicates the strength and direction of a linear relationship. Both can be more easily judged by drawing a straight line through the data. We need an objective method of producing such a straight line. Such a method has been developed; it is called the least squares method.
If we assume there is a linear relationship between two random variables and we try to determine a linear function:
 (
( : the
: the  -intercept,
-intercept,  : the slope of the line)
: the slope of the line)
If  represent the sample observations, then we want to draw the line such that the sum of the squared deviations (residuals) between the obervations and the corresponding points on the line is minimized, thus determine and such that
represent the sample observations, then we want to draw the line such that the sum of the squared deviations (residuals) between the obervations and the corresponding points on the line is minimized, thus determine and such that  is minimal.
is minimal.
The regression line
We solve the optimization problem by partial differentiation to and of the following function:

After some algebra we get:
 and
and

