Sampling distributions
(Keller 9)
A sample of size  is just one of many possible samples of size . If
is just one of many possible samples of size . If  is the population size and the sample size (≪) then the number of possible different samples equals
is the population size and the sample size (≪) then the number of possible different samples equals 
This number of samples is usually very large. For example, from a population of 1000 objects the number of different samples of size 25 equals  .
.
Most samples have (different) random statistics, e.g.  or
or  . These sample statistics have a probability distribution, the so-called sampling distribution.
. These sample statistics have a probability distribution, the so-called sampling distribution.
Some mathematics
 and
and  are sample statistics. Let us derive the distribution function of . We know that
are sample statistics. Let us derive the distribution function of . We know that  and
and  . Then:
. Then:



So, for the random variable it holds:  and
and 
Earlier we defined for any random variable  :
:

and thus for the random variable we get:

Central Limit Theorem
(Keller 7, 8, 9)
The theorem states that he sampling distribution of the means of random samples drawn from any population is approximately normal for a sufficiently large sample size . The larger the sample size, the more closely the sampling distribution of will resemble a normal distribution.
We will not prove the Central Limit Theorem here, that will be beyond the scope of this crash course. However, we try to make this theorem plausible by verifying it in a number of examples.
If the distribution of the population is normal, then is normally distributed for all sample sizes . If the population is non-normal, then is approximately normal only for larger values of . In most practical situations, a sample size of  may be sufficiently large to allow us to use the normal distribution as an approximation for the sampling distribution of .
may be sufficiently large to allow us to use the normal distribution as an approximation for the sampling distribution of .
Verify Central Limit Theorem (may be skipped)
(Keller 9)
The following is a program in pseudo code.
- Take a first sample of size of a uniform distribution and compute its sample mean
 ;
; - Repeat this
 times and thus get
times and thus get  sample means
sample means  . Also these means are random variables;
. Also these means are random variables; - According to the Central Limit Theorem these random means should be (approximately) normally distributed;
- Verify this graphically by drawing a histogram;
- Verify this by applying a normality test (e.g. Anderson-Darling);
- Repeat 1-5 for
 and notice the differences.
and notice the differences.
The actual program is executed by the programming language R but any programming language will so. Thc code of the R program is as follows:
# Suppose x has a uniform distribution
# n is the sample size, preferably n = 30
n <- 30
# k is the number of such sample means, sufficiently large, e.g. k = 5000
k <- 5000
# According to the Central Limit Theorem
# the k sample means should approximate a normal distribution
z <- numeric(k) # z is a vector with k elements and will contain all k sample means
for (j in 1:k) (z[j] <- mean(runif(n))) # compute the mean of each uniform sample
# show the histogram of these means
hist(z)
# and find out whether the distribution of means is normal
# which is approximately true for n ≥ 30
ad.test(z) # Anderson-Darling test
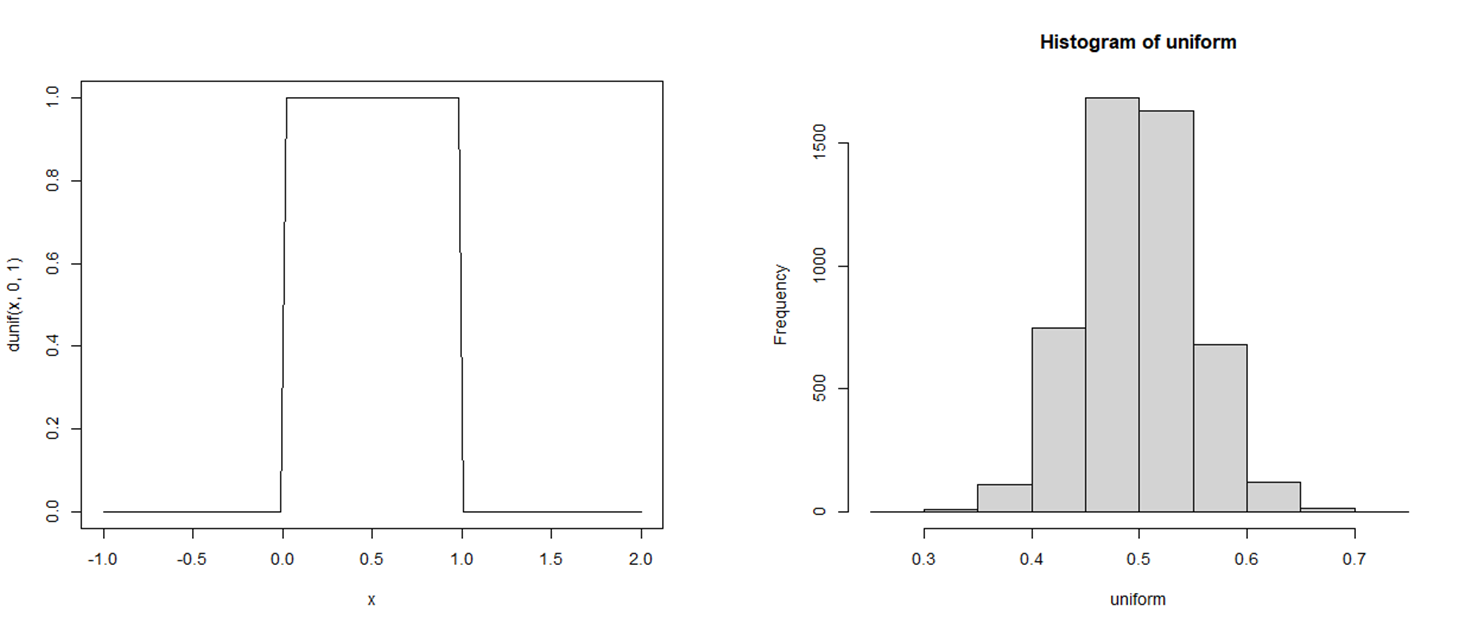
The result is as follows.
The left graph represents a uniform distribution on ![[0,1]](https://4mules.nl/wp-content/ql-cache/quicklatex.com-4ddc1168784a8b723604919df78ae658_l3.png "Rendered by QuickLaTeX.com") ; the right graph depicts a histogram of sample means which is rather good approximation of a normal distribution.
; the right graph depicts a histogram of sample means which is rather good approximation of a normal distribution.
Using the standard normal distribution
(Keller 9)
Suppose the population random variable is normally distributed with  and
and  .
.
We take a sample of size  drawn from the population. The sample mean is denoted by
drawn from the population. The sample mean is denoted by  . We want to compute
. We want to compute  .
.
We know:
is normally distributed, therefore so will be .
 and
and 


The answer can be found in Table 3 of Appendix B9 of Keller.
The difference of two means
(Keller 9)
Consider the sampling distribution of the difference  of two sample means.
of two sample means.
If the random samples are drawn from each of two independent normally distributed populations, then will be normally distributed as well with:



If two populations are not both normally distributed, and the sample sizes are large enough ( ), then in most cases the distribution of is approximately normal (see the Central Limit Theorem).
), then in most cases the distribution of is approximately normal (see the Central Limit Theorem).
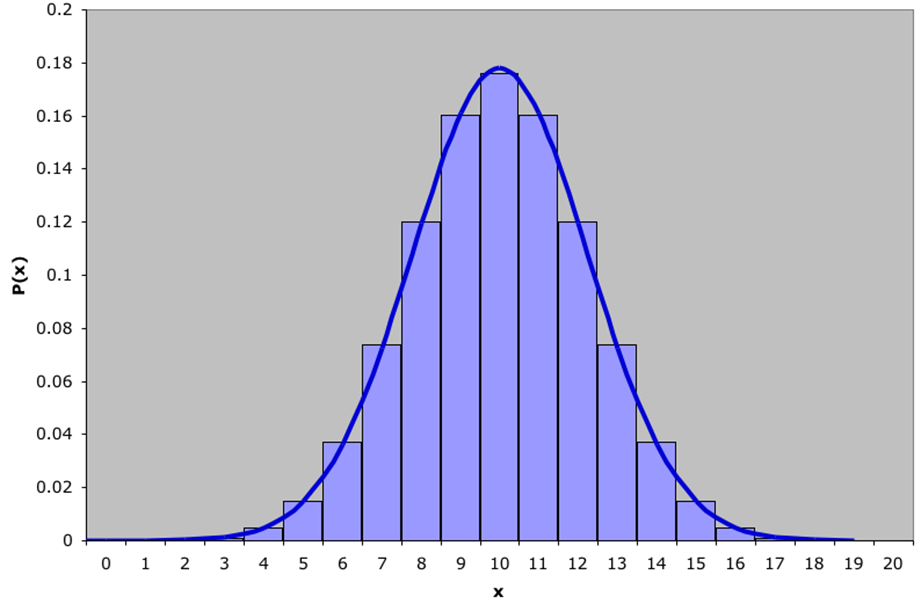
Normal approximation to Binomial
There are circumstances that a Binomial distribution may be approximated by a normal distribution. Let us look at the following example: a binomial distribution with  and
and  (so
(so  and
and  ) superimposed by a normal distribution
) superimposed by a normal distribution  ).
).
The graph shows  and the graph of a
and the graph of a  distribution.
distribution.
The normal approximation to binomial works best when the number of experiments is large and the probability of succes  is close to
is close to  .
.
For the approximation to provide acceptable results two conditions should be met:
 and
and 
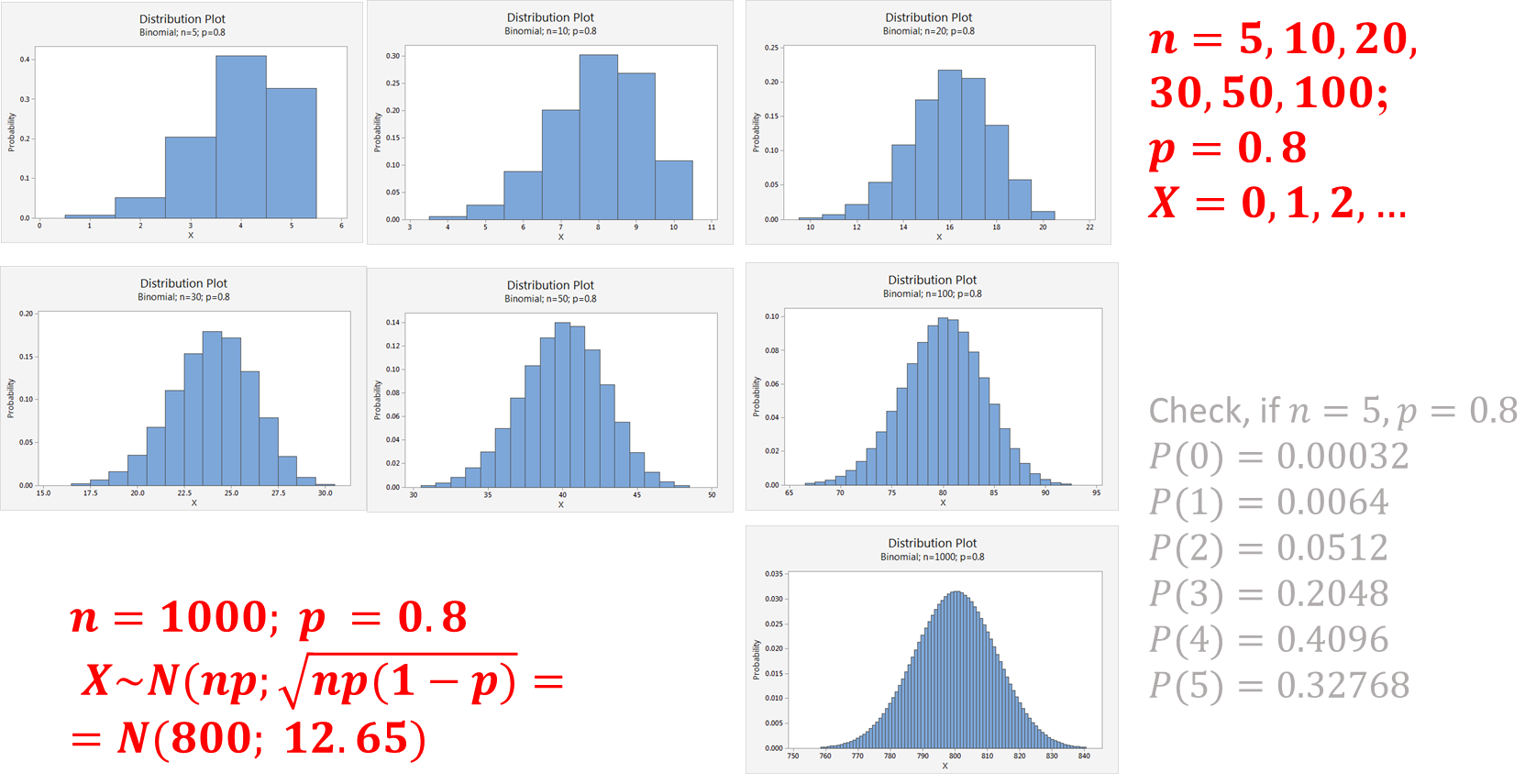
Example
The following graph shows the approximations witp  and various values of .
and various values of .
Example
How accurate is the approximation?
For a binomial distribution ( we find (using Excel):
we find (using Excel): .
.
For a normal distribution ( ) we find:
) we find: (continuity correction), which is pretty close to the exact value.
(continuity correction), which is pretty close to the exact value.
Distribution of a sample proportion
The estimator of a population proportion of successes is the sample proportion. That is, we count the number of successes in a sample of size and compute:

is the number of successes, is the sample size. Note that the random variable has a binomial distribution.
Using the laws of expected value and variance, we can determine the mean, variance and standard deviation. Sample proportions can be standardized to a standard normal distribution using the formula:
 and thus
and thus 
Note.
Binomial disribution: 


and thus:

Example
In the last election a state representative received  % of the votes (so
% of the votes (so  ; this can be considered as a population parameter!)
; this can be considered as a population parameter!)
One year after the election the representative organized a survey that asked a random sample of  people whether they would vote for him in the next election.
people whether they would vote for him in the next election.
If we assume that his popularity has not changed what is the probability that more than half of the sample would vote for him?
The number of respondents who would vote for the representative is a binomial random variable with and and we want to determine the probability that the sample proportion is greater than  %, That is, we want to compute
%, That is, we want to compute  .
.
From the foregoing we know that the sample proportion  is approximately normally distributed with mean and standard deviation
is approximately normally distributed with mean and standard deviation 
Thus we compute:



If we assume that the level of support remains at % the probability that more than half the sample of  people would vote for the representative is
people would vote for the representative is  %.
%.
