In many applications there are more independent linear variables  .
.
Then the model equation is:

and the regression equation is, based on the observation data:

The regression coefficients  are computed by software.
are computed by software.
Example
Let us look at the following example. You want to determine the rate of a room in a new hotel. How would you do that? Relevant parameters are: city, distance of hotel to center or highway, luxury, how many hotels nearby (competitors), how many rooms, rates in other hotels etc.
Build a multiple regression model based on these independent variables  and the dependent variable.
and the dependent variable.
See also General Social Survey (variables that affect income). See Keller p. 686.
Requirements are the same as in univariate models. The coefficient of determination  has the same function. If is close to
has the same function. If is close to  then the model fits the data very well. If is close to
then the model fits the data very well. If is close to  then the model fits the data very poorly. The ANOVA technique tests the validity (the linearity) of the model. The hypotheses for this part are:
then the model fits the data very poorly. The ANOVA technique tests the validity (the linearity) of the model. The hypotheses for this part are:
 ;
;
 at least one
at least one  .
.
If the test statistic  (the rejection region), then reject
(the rejection region), then reject  and at least one
and at least one  ,meaning that the model is valid (there is a linear relation with at least one ).
,meaning that the model is valid (there is a linear relation with at least one ).
Testing the individual coefficients
For each individual independent variable, we can test whether there is enough evidence of a linear relationship between the output  and a specific input variable ..
and a specific input variable ..
The hypotheses are:

The test statistic is:

If  or
or  then reject .
then reject .
Note. Reject if  or
or  .
.
Multicollinearity
Multiple regression models have a problem that simple regression models do not have, namely multicollinearity. It happens when one or more independent variables are (highly) correlated.
The adverse effect of multicollinearity is that the estimated regression coefficients of the independent variables that are correlated, tend to have large sampling errors.
Example
A linear model expresses the relation of someone's lottery expenses (dependent variable ) and a number of characteristics such as Education, Age, Children and Income (independent variables). The table below shows that the correlations between the variables (Income, Education) and (Age, Education) are significant, leading to multicollinearity.

Nonlinear models
Regression analysis is used for linear models using interval data, but regression analysis can also be used for: non-linear (e.g. polynomial) models, and models that include nominal (also called dummy) independent variables,
Previously we looked at this multiple regression model:

The independent variables may be functions of a smaller number of so-called predictor variables. Polynomial models fall into this category. If there is one predictor value  we have:
we have:

We can rewrite this polynomial model:

Two predictor variables (linear and quadratic)
Suppose we assume that there are two predictor variables  and
and  which linearly influence the dependent variable . Then we can distinguish between two types of models.
which linearly influence the dependent variable . Then we can distinguish between two types of models.
One is a first order model without interaction between and .

The second model is with interaction between  and
and  .
.

Usually, we cannot give a meaning to the interaction term.
If we assume a quadratic relationship between and each of and , and that these predictor variables interact in their effect on , we can use this second order model (with two independent variables) with interaction:

Example
We want to build a regression model for a fast food restaurant and know that its primary market is middle income adults and their children, particularly those between the ages of 5 and 12. In this case the dependent varuable is the restaurant revenue and the predictor variables are family income and the age of children. A question is whether the relationship is first order, quadratic, with or without interaction. The significance level is  %.
%.
An indication for a quadratic relationship can be found in the scatterplots. You can take the original data collected (revenues, household income, and age) and plot vs. and vs. to get a feel for the data, with the following results.

Based on the graphs we prefer a second order model (with interaction):
although we cannot give a meaning to the interaction term.
The result is given in the following Excel table.
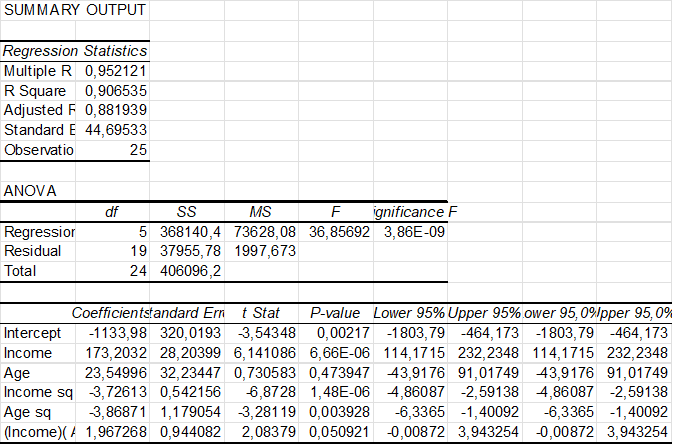
The coefficient of determination  is rather high indicating that the model fits the data very well. The
is rather high indicating that the model fits the data very well. The  value of
value of  is very small
is very small  , so the model is valid (at least one coeffincient is unequal zero). The coefficients Income, Income sq, Age sq have very small values and may be assumed to be linearly related. Age and IncomeAge don’t seem to be linearly related, because their
, so the model is valid (at least one coeffincient is unequal zero). The coefficients Income, Income sq, Age sq have very small values and may be assumed to be linearly related. Age and IncomeAge don’t seem to be linearly related, because their  are greater than 0.05. Note. Reject
are greater than 0.05. Note. Reject  variable
variable  if
if  (two-sided test).
(two-sided test).
So, we may conclude that the model fits the data very well, is valid and the coefficients of the variables Age and IncomeAge might be assumed to be 0 amd thus these variables do not seem to be releated to the revenu.
Nominal variables
Thus far in our regression analysis, we have only considered interval variables. Often however, we need to consider nominal data in our analysis. For example, our earlier example regarding the market for used cars focused only on the interval variable Odometer. But the nominal variable color may be an important factor as well. How can we model this new nominal variable?
An indicator variable (also called a dummy variable) is a variable that can assume either one of only two values (usually 0 and 1). A value of 1 usually indicates the existence of a certain condition, while a value of 0 usually indicates that the condition does not hold.
| Car color |  |  |
| white | 1 | 0 |
| silver | 0 | 1 |
| other | 0 | 0 |
| two-tone | 1 | 1 |
Let us consider the difference between the regression models without and with color. See the following Excel output.
Without color
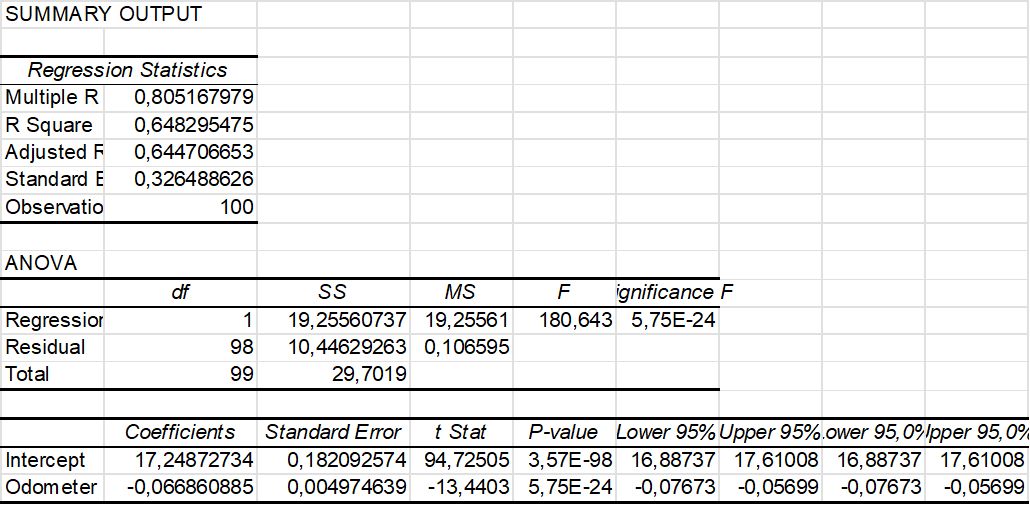
With color

In the case 'without color' the coefficient of determination is less than in the case 'with color'. The latter model fits the data a bit better. Another conclusion is that a white car sells for 91.10 dollars more than other colors and a silver car sells for 330.40 dollars more than other colors (*). However, for the value of  we have
we have  so it seems that the color white does not seem to be related to the price.
so it seems that the color white does not seem to be related to the price.
