There are two hypotheses, the null hypothesis  and the alternative or research hypothesis
and the alternative or research hypothesis  or
or  . The procedure begins with the assumption that the null hypothesis is true and the goal is to determine whether there is enough evidence to support the alternative hypothesis. There are two possible decisions:
. The procedure begins with the assumption that the null hypothesis is true and the goal is to determine whether there is enough evidence to support the alternative hypothesis. There are two possible decisions:
- There is enough evidence to support the alternative hypothesis and to reject the null hypothesis; or
- There is not enough evidence to support the alternative hypothesis and to not reject the null hypothesis.
The procedure
- Collect sampling data (e.g.
 );
); - Calculate some statistic, e.g.
 if the hypothesis is about the population mean
if the hypothesis is about the population mean  ;
; - See whether the statistic is extreme or is seen as “bad luck”, given ( is assumed to be correct);
- If extreme, reject ;
- If not extreme, do not reject .
So, reject when the result is extreme, but what is extreme? We consider extreme: (very) unlikely under . However how unlikely is unlikely? This choice has to made by the statistician: the significance level  . This is usually set at
. This is usually set at  % but also
% but also  % or
% or  % are common.
% are common.
Reject if the statistic is in the tail of the distribution under We can also say: if is correct, reject in % of the cases.
Potential errors
There are two types of error.
Type I error
Reject while is correct.
Based on the data you find the result extreme and reject but after all appears to be correct.
Type II error
Do not reject while is not correct.
Based on the data you find the result “acceptable” and you do not reject but after all appears not to be correct.
Example

The Dutch coffee brewer Douwe Egberts sells packs of coffee. It claims that the mean weight of the packs is 250 grams or more. The population standard deviation is known:  grams. To verify this claim we take a sample of
grams. To verify this claim we take a sample of  packs.
packs.
What would we decide if you find  grams? Reject or not reject ? And why?
grams? Reject or not reject ? And why?
This is one-sided problem.
We have the following data: packs
packs 250 grams (the claim) grams grams
250 grams (the claim) grams grams grams;
grams;  grams
grams
We compute the probability of 'bad luck', i.e. we assume is true and yet we find  :
:


This means that if such a sample would be taken every day during about 3 years, only once the result would be  grams or less. Would we decide this as 'very unlikely under '? What would we decide: reject or not reject ?
grams or less. Would we decide this as 'very unlikely under '? What would we decide: reject or not reject ?
If we would decide the probability  is too small to not reject the null hypothesis, what probability would be acceptable:
is too small to not reject the null hypothesis, what probability would be acceptable:  ,
,  ,
,  ? This choice is determined by the significance level . A common choice is
? This choice is determined by the significance level . A common choice is  . In this case we find the sample mean very extreme under and would reject the null hypothesis.
. In this case we find the sample mean very extreme under and would reject the null hypothesis.
Example

Now we consider a pair of nuts and bolts. The manufacturer claims that the diameter of the bolts is 1 cm, not larger or smaller. The population standard deviation is  cm. To verify this claim we take a sample of bolts.
cm. To verify this claim we take a sample of bolts.
What would we decide if we find  cm. Reject or not reject ? And why? This is two-sided problem.
cm. Reject or not reject ? And why? This is two-sided problem.
We have the following data:
bolts cm cm cm
cm cm cm cm;
cm;  cm
cm
We compute the probability of 'bad luck', i.e. is true and yet we find  :
:


Again we would reject the null hypothesis.
Suppose that the sample mean would be  Then we would find:
Then we would find:
and we would again reject the null hypothesis.
If the significance level , in the one-sided coffee case we would reject the null hypothesis because  , namely (
, namely ( ).
).
In the nuts and bolts case we would reject the null hypothesis if  (
( ) (both too large or too small is not acceptable).
) (both too large or too small is not acceptable).
Rejection region
The rejection region is a range of values such that if the test statistic falls into that range, we decide to reject the null hypothesis in favor of the alternative hypothesis. The rejection region is usually used when the test is carried out manually.
One-sided or two-sided
Depending on the alternative hypothesis the test is either one-sided or two-sided.
If  or
or  the hypothesis test is called one-sided.
the hypothesis test is called one-sided.
If  the hypothesis test is called two-sided.
the hypothesis test is called two-sided.
Strategies to perform the test
Strategy 1: Use the rejection region if the test is carried out manually.
- Choose the significance level ;
- Calculate the test statistic, e.g. based on ;
- Calculate the rejection region;
- Reject if the test statistic is in the rejection region.
Strategy 2: use the  -value if the test is carried out by computer.
-value if the test is carried out by computer.
- Choose the significance level ;
- Calculate the test statistic, e.g. based on ;
- Calculate its probability under which results in a -value;
- Reject if (one-sided) or (two-sided).
The Z test
If we want to perform a one-sided hypothesis test with:

and  is known, then use the data to compute and compute the test statistic:
is known, then use the data to compute and compute the test statistic:
 .
.
Define  from
from  .
.
The rejection region is  and reject if
and reject if  falls into the rejection region. Often used values are:
falls into the rejection region. Often used values are:  (one-sided) and
(one-sided) and  (two-sided). See Keller, table B.3.
(two-sided). See Keller, table B.3.
If we want to perform a one-sided hypothesis test with:

and is known, then use the data to compute and compute the test statistic:
.
Define from  .
.
The rejection region is  and reject if falls into the rejection region.
and reject if falls into the rejection region.
If we want to perform a two-sided hypothesis test with:

and is known, then use the data to compute and compute the test statistic:
.
Define  from
from  .
.
The rejection region is  or
or  and reject if falls into the rejection region.
and reject if falls into the rejection region.
We look at the rejection region vs. the -value and consider again the one-sided test of the previous coffee examples.
Strategy 1 (one-sided)
First we look at the case .

The test statistic is:


The rejection region is:
 .
.
The test statistic is in the rejection region.
Conclusion: reject .
Now the case 

The test statistic is:

The rejection region is:
.
The test statistic is not in the rejection region.
Conclusion: do not reject .
Strategy 2 (one-sided)
First we look at the case .
The test statistic is:
We find:

Since:

we reject the null hypothesis .
Now we consider the case .
The test statistic is:

We find:

Since:


we do not reject the null hypothesis .
Now we look at the two-sided test of the nuts and bolts example.
Strategy 1 (two-sided)

The test statistic is:

The rejection region is:
 or
or  .
.
The test statistic is in the rejection region. So, we reject the null hypothesis
Strategy 2 (two-sided)
Now we look at the case when  .
.

The significance level is , so 
The test statistic is:

We find  .
.
So, the -value equals  . Since
. Since 
 we do not reject the null hypothesis .
we do not reject the null hypothesis .
What if the population is not normal?
Suppose that the requirement  is normally distributed is violated? In cases where
is normally distributed is violated? In cases where  is large (about
is large (about  or more) this is not really a problem because of the Central Limit Theorem. If is not large enough we can't rely on the -test. Then we need to use so-called nonparametric tests, e.g. the Wilcoxon signed rank test.
or more) this is not really a problem because of the Central Limit Theorem. If is not large enough we can't rely on the -test. Then we need to use so-called nonparametric tests, e.g. the Wilcoxon signed rank test.
Hypothesis testing, unknown population variance
Thus far the population standard deviation is assumed to be known and then we could use the test statistic:

If is unknown which is almost always the case, we use ’s point estimator  instead and get the test statistic:
instead and get the test statistic:

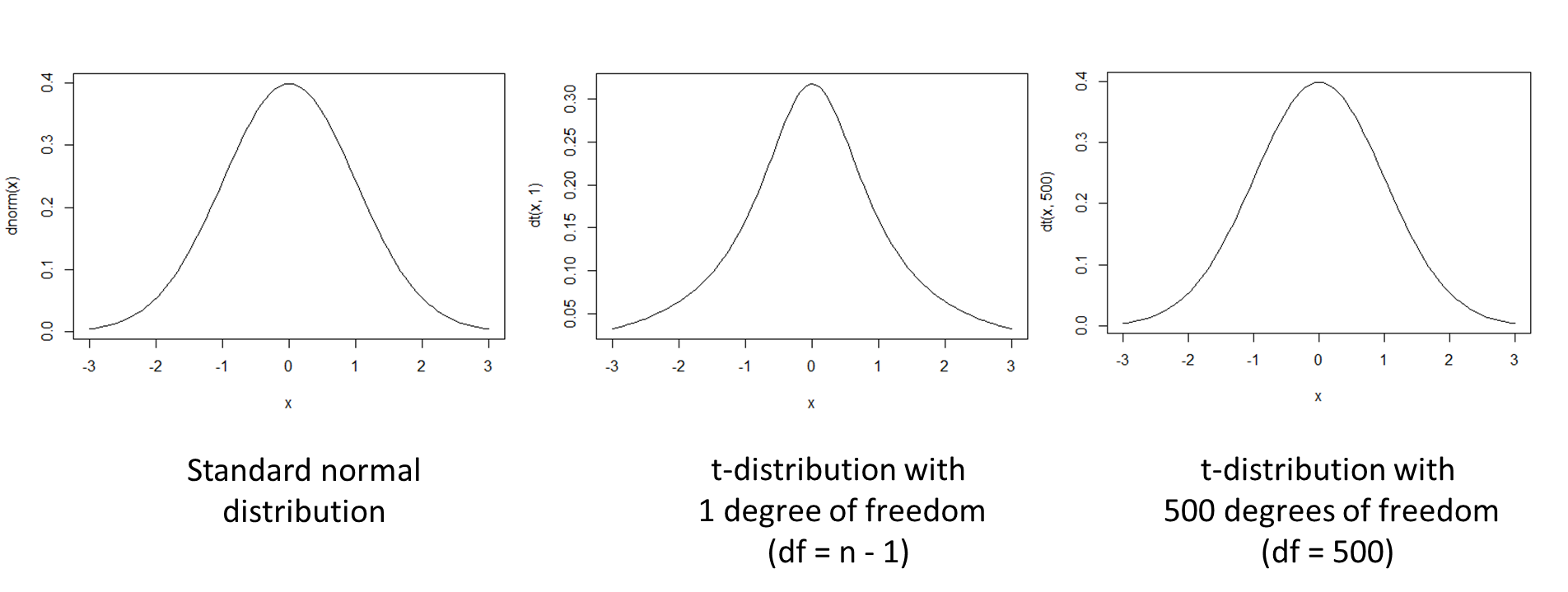
which has a so-called Student's  -distribution.
-distribution.  is called degrees of freedom, written as
is called degrees of freedom, written as  or
or  . All distributions
. All distributions  have a symmetrical graph around
have a symmetrical graph around  and approximate the standard normal distribution
and approximate the standard normal distribution  for larger :
for larger :

See also the graphgs below.
If the population standard deviation is unknown, and the population is normally distributed, then the confidence interval estimator of is given by:

The t test
If we want to perform a one-sided hypothesis test with:

then use the data to compute and and the test statistic:

Next, find  and the rejection region is
and the rejection region is

Reject if falls into the rejection region
Use a similar approach when  and If the test is two-sided use
and If the test is two-sided use 
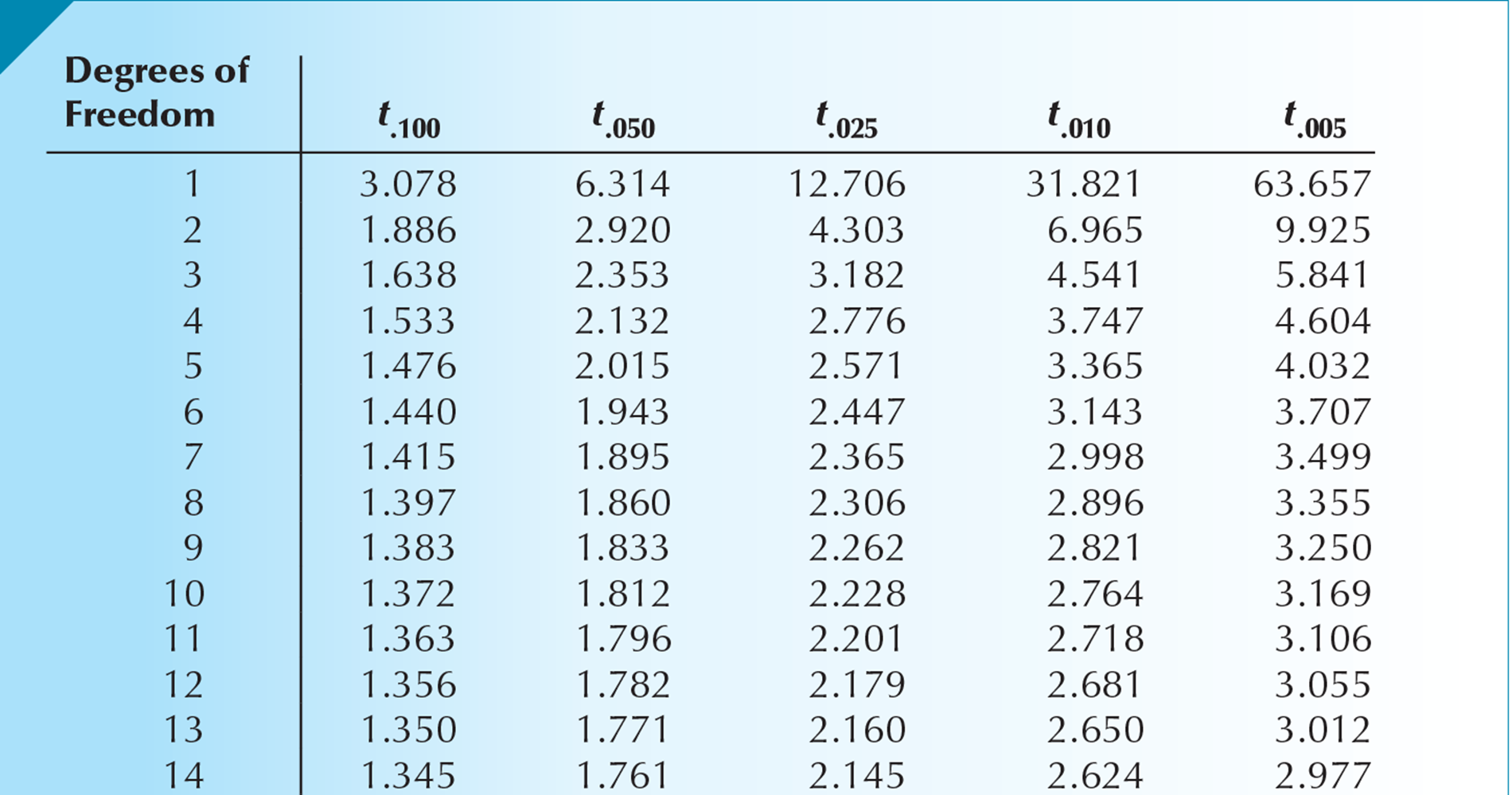
Example
If  then
then 


See the table below.
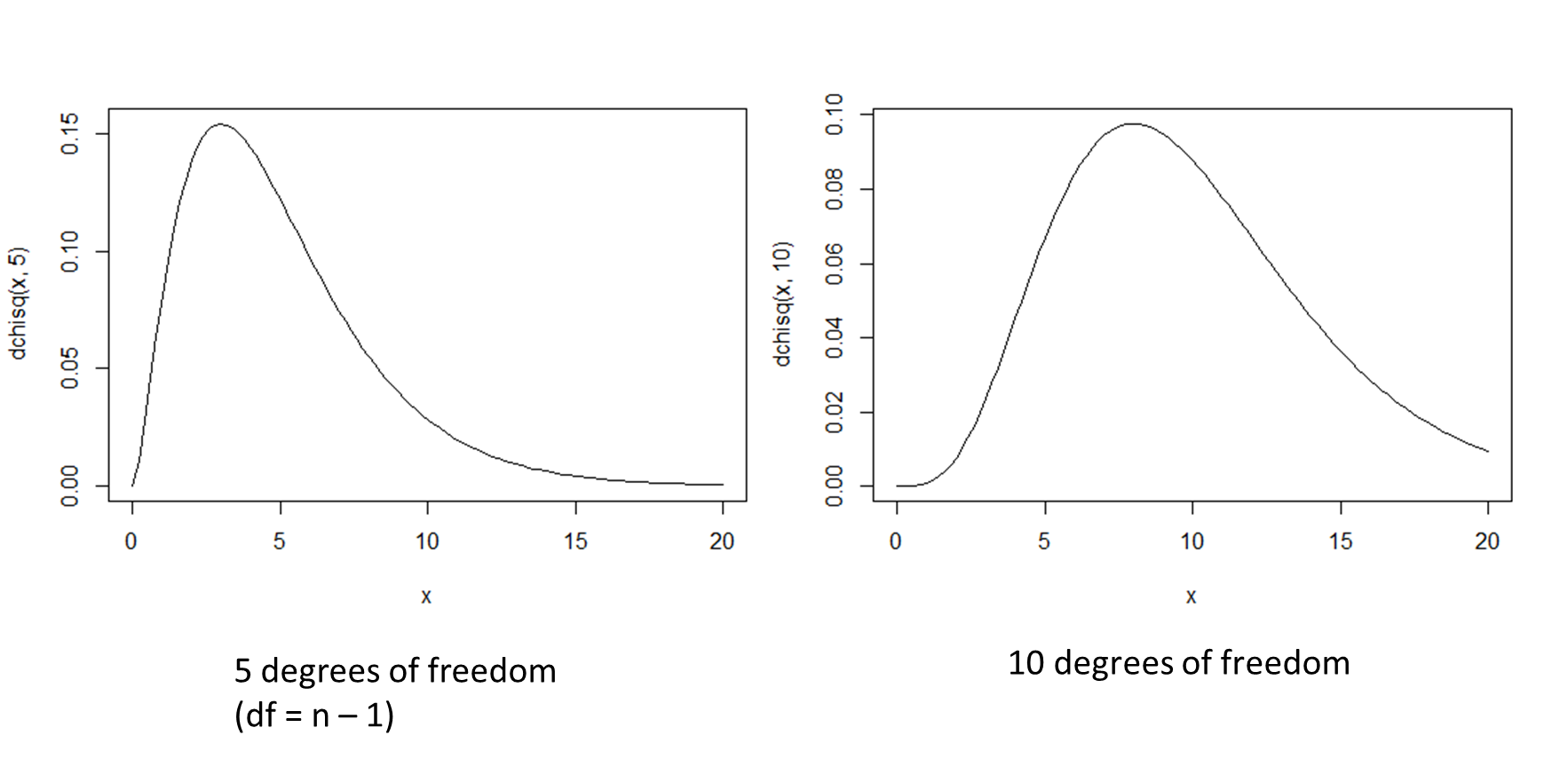
Inference about the population variance
If we are interested in drawing inferences about a population’s variability, the parameter we need to investigate is the population variance. The sample variance  is an unbiased, consistent and efficient point estimator of
is an unbiased, consistent and efficient point estimator of  . Moreover, the test statistic:
. Moreover, the test statistic:

has a  distribution with
distribution with  degrees of freedom.
degrees of freedom.
Confidence interval of the variance
Combining the test statistic:
with the probability statement:

yields the confidence interval estimator for :
Lower confidence Limit  Upper confidence limit:
Upper confidence limit:

Graphs of the Chi-squared distribution
What does the procedure look like in the one-sided (left and right) or two-sided case.
One-sided left
In this case we have:

and the significance level is .
Compute the test statistic:
and find (use table 5, p. B-11):

The rejection region is
 .
.
And thus reject if:

One-sided right
The procedure is similar. In this case we have:

and the significance level is .
Compute the test statistic:
and find (use table 5, p. B-11)  . The rejection region is:
. The rejection region is:
 .
.
And thus reject if

Two-sided
In this case we have:

and the significance level is .
Compute the test statistic:
and find (use table 5, p. B-11)  and
and  .
.
The rejection region is:
 or
or 
And thus reject if falls into the rejection region.
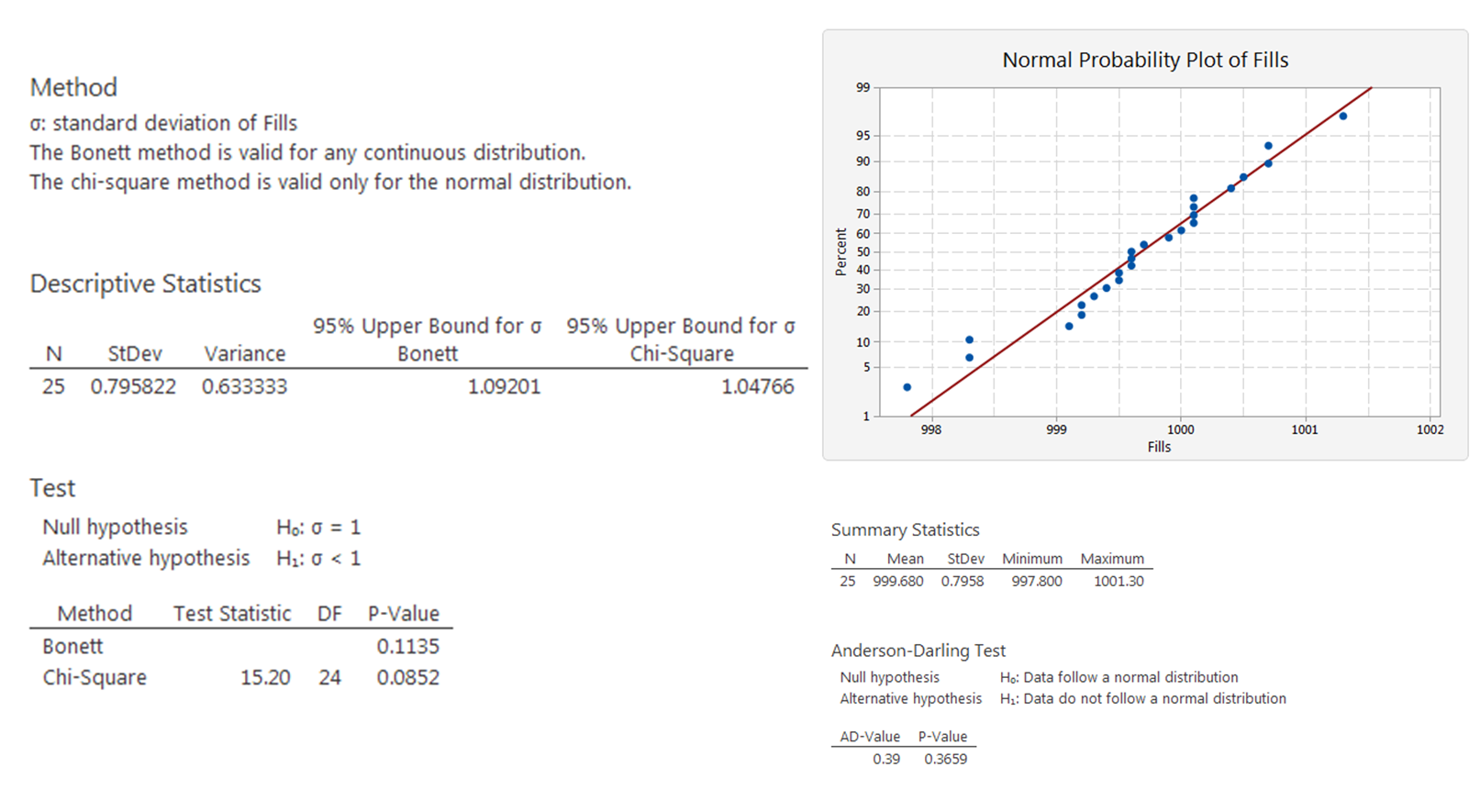
A container filling machine
Container-filling machines are used to package a variety of liquids, including milk, soft drinks, or paint. Ideally, the amount of liquid should vary only slightly, since large variations will cause some containers to be underfilled and some to be overfilled (resulting in a mess).
The president of a company that developed a new type of machine boasts that this machine can fill 1 liter (1,000 cubic centimeters) containers so consistently that the variance of the fills will be less than 1 cubic centimeter.
A sample of 25 fills of 1 liter was taken showing  .
.
The null and alternative hypotheses are:

The test statistic is:

The rejection region is:

The test statistic  is not less than 13.85 and thus not in the rejection region, so we do not reject the null hypothesis in favor of the alternative hypothesis.
is not less than 13.85 and thus not in the rejection region, so we do not reject the null hypothesis in favor of the alternative hypothesis.
This example has been computed by Minitab Express with the following results. Just look at the data, because the Anderson-Darling test shows that the data are normally distributed. The computed  so we will not reject the null hypothesis.
so we will not reject the null hypothesis.
Also the programming language R can do the job. See the program below.

Test statistic for proportions
If is the sample size, is the assumed population proportion and  (
( the number of successes in the sample) is the estimate of , then the test statistic for proportions is:
the number of successes in the sample) is the estimate of , then the test statistic for proportions is:

which is approximately normal when  and
and  are both greater than 5. (Note: the normal approximation of binomial distribution).
are both greater than 5. (Note: the normal approximation of binomial distribution).
Compare this formula with:

To understand the test statistic for proportions, recall the following (binomial) formulas:
 ;
; 
 ;
; 

Example: An exit poll
An exit poll of  voters showed that
voters showed that 
 voted for the Republican candidate. Thus:
voted for the Republican candidate. Thus:

Suppose  , (Dems win);
, (Dems win);  (Reps win).
(Reps win).
The test statistic is:

If the signicance level is  % we know that the rejection region is
% we know that the rejection region is  . Because is in the rejection region we reject the null hypothesis.
. Because is in the rejection region we reject the null hypothesis.
So, there is enough evidence at the 5% significance level that the Republican candidate will win.
