Following we will look at comparing and testing two or more populations.
- Comparing the means
 and
and  ;
; - Comparing the variances
 and
and  ;
; - Comparing the proportions
 and
and  .
.
We also compare the means of three or more populations (ANOVA).
Previously we looked at techniques to estimate and test parameters of one population:
- Population mean
 ;
; - Population variance
 ;
; - Population proportion
 .
.
We will still consider these parameters when looking at two populations or more, however, our interest will now be:
- The difference of two population means
 ;
; - The ratio of two population variances
 ;
; - The difference of two population proportions
 .
.
Comparing two population means
If we compare two population means, we use the statistic 
 is an unbiased and consistent estimator of ;
is an unbiased and consistent estimator of ; is an unbiased and consistent estimator of ;
is an unbiased and consistent estimator of ;- Then is an unbiased and consistent estimator of .
Note. Usually, the sample sizes  and
and  are not equal.
are not equal.
We consider two cases.
- Independent populations. The data in one population are independent of the data in the other population;
- Matched pairs. Observations in one sample are matched with observations in the second sample, so the samples are not independent.
Independent populations
The random variable  is normally distributed if the original populations are normal or approximately normal if the populations are nonnormal and the sample sizes are large enough (
is normally distributed if the original populations are normal or approximately normal if the populations are nonnormal and the sample sizes are large enough ( , Central Limit Theorem).
, Central Limit Theorem).
Earlier we derived:


So, the standard error is:

If  is (approximately) normally distributed and
is (approximately) normally distributed and  are known, then the test statistic is:
are known, then the test statistic is:

which is a (approximately) standard normally distributed random variable.
We use this test statistic and the confidence interval estimator for .
In practice, the  statistic is rarely used since usually the population variances
statistic is rarely used since usually the population variances  and
and  are unknown. Then, instead we use the
are unknown. Then, instead we use the  statistic for and apply the point estimators
statistic for and apply the point estimators  and
and  for and , respectively. However, this statistic depends on whether the unknown variances and are equal or not.
for and , respectively. However, this statistic depends on whether the unknown variances and are equal or not.
Equal, unknown population variances
The test statistic in the case of equal, unknown variances is:


 is the pooled variance;
is the pooled variance;  are the degrees of freedom.
are the degrees of freedom.
In fact, the pooled variance is the weighted mean of  and
and  , the sample sizes
, the sample sizes  and
and  are the weight factors.
are the weight factors.
Note. Just check: if  then
then  as expected.
as expected.
The confidence interval for if the population variances are equal ( ):
):

The degrees of freedom are .
The degrees of freedom  is a complicated formula, see Keller, p. 441.
is a complicated formula, see Keller, p. 441.
Note.  . Larger degrees of freedom have the same effect as having larger sample sizes. So the equal variances test – if possible - is to be preferred (more accurate).
. Larger degrees of freedom have the same effect as having larger sample sizes. So the equal variances test – if possible - is to be preferred (more accurate).
Inference about variances
Since the equal variances test is to be preferred, we want to find out whether the population variances can be assumed to be equal:  ? How do we find out?
? How do we find out?
Fortunately, there is a test for this in which the ratio of the variances is used:  .
.
To find out whether the variances  and
and  are equal the so-called
are equal the so-called  test is used. The sampling statistic is:
test is used. The sampling statistic is:

which has a distribution with  and
and  degrees of freedom.
degrees of freedom.
The null hypothesis always is  , i.e. the variances of the two populations are assumed to be equal. Therefore, the test statistic reduces to:
, i.e. the variances of the two populations are assumed to be equal. Therefore, the test statistic reduces to:

with and degrees of freedom.
An example of the distributions  and
and  :
:

Testing the population variances
The easiest way to solve this problem is the following procedure:
- The hypotheses are:
 .
. - Choose the test statistic
 such that
such that  .
. - Then the rejection region is
 .
.
Reject  if falls into the rejection region.
if falls into the rejection region.
Comparing two population means
Follow the following procedure:
- If the variances
 and
and  are known: apply the test.
are known: apply the test. - If the variances and are unknown.
- To find out whether they can be assumed to be equal apply the equal-variances test.
- If the variances can be assumed to be equal: use the pooled variances test.
- If the variances cannot be assumed to be equal, use the unequal variances test.
- To find out whether they can be assumed to be equal apply the equal-variances
Grolsch vs. Heineken (known variances)
Some students claim that on the average a Grolsch barrel ( ) of beer contains more beer than a Heineken barrel (
) of beer contains more beer than a Heineken barrel ( ). Both brewers claim that a barrel of beer contains
). Both brewers claim that a barrel of beer contains  liters or more.
liters or more.
Now we have the hypotheses:
 ;
; 
The students want to investigate this claim and use a sample of 9 barrels of Grolsch and 16 barrels of Heineken and find:
 liter and
liter and  .
.
The population standard deviations are assumed to be known:
 liter and
liter and  liter.
liter.
Now we have:
 ,
,  ,
,  ,
, 
 ,
,  ,
,  ,
, 
The significance level is  .
.
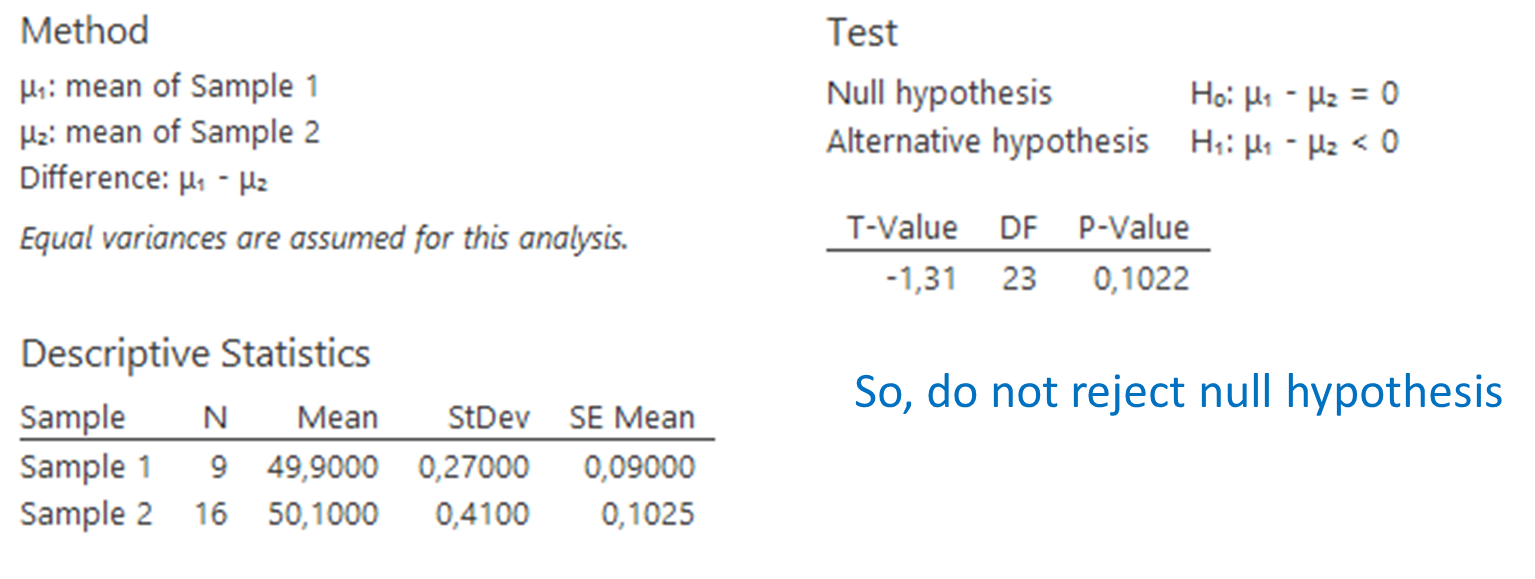
We compute the statistic (known variances) and find:

The rejection region is  .
.
The test statistic does not fall into the rejection region and thus there is insufficient evidence to reject 
Minitab Express finds the following result:

Grolsch vs. Heineken (unknown variances)
Suppose we do not know the population variances. Then we need to verify whether we may assume the variances to be equal. This test is carried out by Minitab Express and shows that we may assume the unknown variances to be equal.
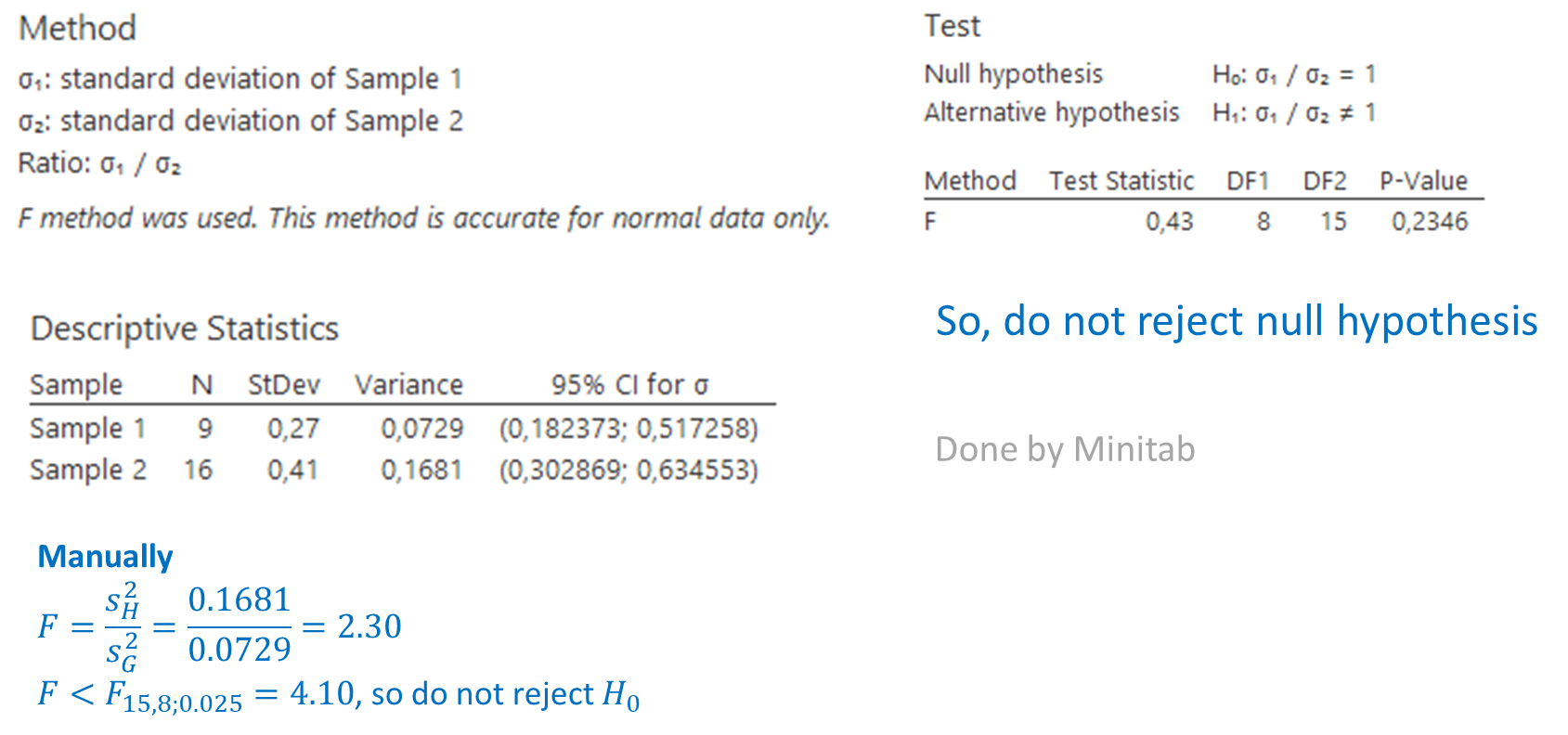
Now we may use the pooled test statistic and find:

The rejection region is:
![t<-t_{23;0.05]=-1.714](https://4mules.nl/wp-content/ql-cache/quicklatex.com-1d79dcc41beafe771b849d4550d761de_l3.png "Rendered by QuickLaTeX.com")
Again, there is insufficient evidence to reject .
Minitab Express confirms this result:
Matched pairs
We illustrate this case by the following example.
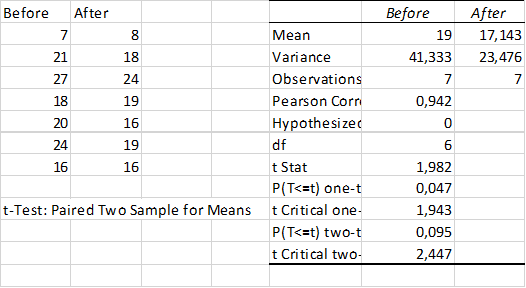
In a preliminary study to determine whether the installation of a camera designed to catch cars that go through red lights affects the number of violators, the number of red-light runners was recorded for each day of the week before and after the camera was installed.
| Day | Before | After | Difference |
| Sunday | 7 | 8 | -1 |
| Monday | 21 | 18 | +3 |
| Tuesday | 27 | 24 | +3 |
| Wednesday | 18 | 19 | -1 |
| Thursday | 20 | 16 | +4 |
| Friday | 24 | 19 | +5 |
| Saturday | 16 | 16 | 0 |
| Total | 13 |
Can we infer that the camera reduces the number of red-light runners? Obviously, the samples ‘before’ and ‘after’ are not independent. The purpose of the installation is that the number of red-light runners ‘after’ will be less than ‘before’, so:
 the difference ‘means before’ – ‘means after’
the difference ‘means before’ – ‘means after’

In this experimental design the parameter of interest is the mean of the population of differences  .
.
The test statistic for the mean of the population differences is:

which is Student’s distributed with  degrees of freedom, provided that the differences are (approximately) normally distributed.
degrees of freedom, provided that the differences are (approximately) normally distributed.
We compute the mean of the differences:  and the sample standard deviation:
and the sample standard deviation:  . The test statistic is:
. The test statistic is:

The rejection region is 
The test statistic falls into the rejection region, so reject . The installation seems to reduce the red-light runners although there is no overwhelming evidence (see also the Excel output below).
Difference between two proportions
If  and
and  are the number of successes in samples of sizes and , then:
are the number of successes in samples of sizes and , then:


estimate the population proportions and respectively. The sampling distribution of  is (approximately) normally distributed provided some requirements hold. The following formulas hold:
is (approximately) normally distributed provided some requirements hold. The following formulas hold:


so, the test statistic is:

which is (approximately) standard normally distributed.
We consider two cases:
1.  and 2.
and 2. 
Case 1
If 
then we assume  and then we use the pooled proportion estimate:
and then we use the pooled proportion estimate:

which leads to the following test statistic:

Case 2
If 
then we use the following test statistic:

Example
Suppose:



The pooled proportion is:

The pooled test statistic is:


The rejection region is 
The test statistic falls into the rejection region and thus at the  % significance level the null hypothesis is rejected.
% significance level the null hypothesis is rejected.
Analysis Of Variance: ANOVA
Analysis of variance is a technique that allows us to compare two or more populations of interval data:

ANOVA is an extension of the previous ‘compare means’ problems which is only for two populations.
ANOVA is a procedure which determines whether differences exist between population means. It works by analyzing the sample variances.
Independent samples are drawn from  populations:
populations:

The populations are referred to as treatments (for historical reasons).  is the response variable and its values are responses.
is the response variable and its values are responses.
 refers to the
refers to the  observation (row) in the
observation (row) in the  sample (column). E.g.
sample (column). E.g.  is the
is the  rd observation in the th sample.
rd observation in the th sample.
The grand mean  is the mean of all observations:
is the mean of all observations:

with 
One-way ANOVA: Stock market
A financial analyst randomly sampled 366 American households and asked each to report the age of the head of the household and the proportion of their financial assets that are invested in the stock market.
The age categories are:
- Young (Under 35);
- Early middle-age (35 to 49);
- Late middle-age (50 to 65);
- Senior (Over 65).
The analyst was particularly interested in determining whether there are differences in stock ownership between the age groups.
The percentage of total assets invested in the stock market is the response variable; the actual percentages are the responses in this example.
Population classification criterion is called a factor.
- The Age category is the factor we are interested in;
- Each population is a factor level;
- In this example, there are four factor levels: Young, Early middle age, Late middle age, and Senior.
The hypotheses are:

 at least two means differ
at least two means differ
Since  is of interest to us, a statistic that measures the proximity of the sample means to each other would also be of interest.
is of interest to us, a statistic that measures the proximity of the sample means to each other would also be of interest.
Such a statistic exists, and is called the between-treatments variation.
The between-treatments variation is denoted  , short for “Sum of Squares for Treatments”. It is calculated as:
, short for “Sum of Squares for Treatments”. It is calculated as:

If  are equal then
are equal then  and
and  . A large indicates large variations between sample means which supports
. A large indicates large variations between sample means which supports  .
.
A second statistic,  (Sum of Squares for Error) measures the within-treatments variation.
(Sum of Squares for Error) measures the within-treatments variation.

or

In the second formulation, it is easier to see that it provides a measure of the amount of variation we can expect from the random variable we have observed.
The total variation (of all observations) is:
 (Total)}
(Total)}
We can prove:
(Total) 
Since:
and if:

then:

and our null hypothesis:
would be supported.
More generally, a small value of supports the null hypothesis. A large value of supports the alternative hypothesis. The question is, how large is “large enough”?
If we define the mean square for treatments:

and the mean square for error:

then the test statistic:

has a distribution wih  and
and  degrees of freedom.
degrees of freedom.
In example 14.1 (Keller) we calculated:

and:

and thus the test statistic is:

The rejection region is:

The test statistic falls into the rejection region, so we reject .
The following plot shows the details.
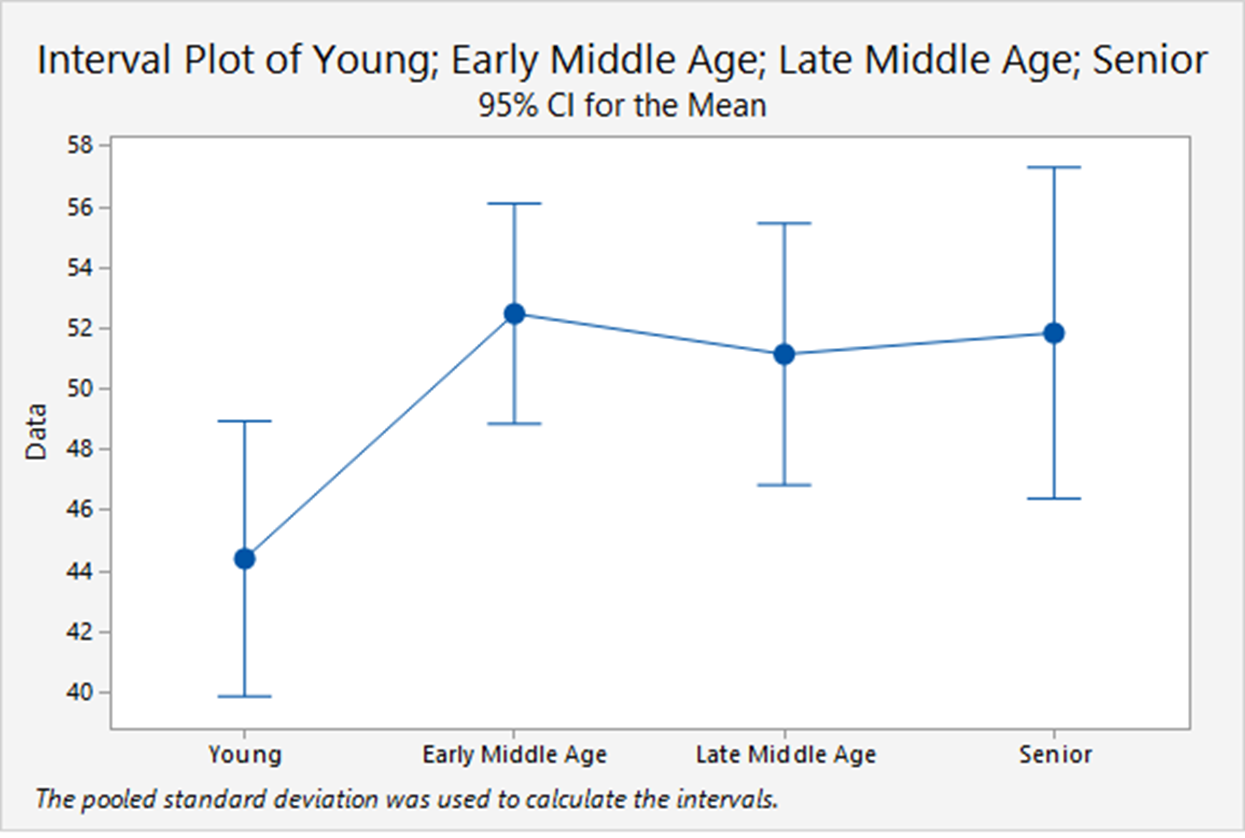
and Excel gives the following results. Note the relation between  and the -value.
and the -value.

In general, the results of ANOVA are usually reported in an ANOVA table as can be seen in the Excel output.
| Source of Variation | Degrees of freedom | Sum of Squares | Mean Square |
| Treatments | k–1 | SST | MST=SST/(k–1) |
| Error | n–k | SSE | MSE=SSE/(n–k) |
| Total | n–1 | SS(Total) |
One question has to be answered. In this case, what do we need ANOVA for? Why not test every pair of means? For example, say  . Then there are
. Then there are  different pairs of means,
different pairs of means,
1&2 1&3 1&4 1&5 1&6
2&3 2&4 2&5 2&6
3&4 3&5 3&6
4&5 4&6
5&6
If we test each pair with we increase the probability of making a Type I error. If there are no differences then the probability of making at least one Type I error is

